Introduction
Vous avez déjà ouvert un binaire dans IDA Pro et cliqué sur F5 pour voir votre beau code C apparaître comme par magie ? C'est le cauchemar de n'importe quel développeur qui veut protéger sa propriété intellectuelle ou son système de licence.
On connaît tous l'obfuscation de base : renommer des fonctions, ajouter des sauts inutiles... mais aujourd'hui, on va parler du "boss final" : l'obfuscation par virtualisation.
Cette approche est la base de protections bien connues comme VMProtect ou Themida, et l'un des piliers de Denuvo pour retarder le crack des jeux AAA. L'idée est simple mais brutale : on supprime le code natif que votre processeur (Intel/AMD) comprend, et on le remplace par un langage propriétaire que seule une machine virtuelle (VM) injectée dans le programme peut interpréter.
⚠️ Ce post est une analyse technique pour comprendre comment on construit un tel système. On va prendre comme exemple un petit obfuscateur maison en Rust. ⚠️
1. Le problème : la transparence du natif
Quand vous compilez une fonction simple comme celle-ci :
int check_logic(int input) {
return input + 42;
}
Le compilateur génère ça en x86_64 :
mov eax, edi ; On met l'argument dans EAX
add eax, 42 ; On ajoute 42
ret ; On revient au parent
C'est immédiatement compréhensible. N'importe quel outil de reverse engineering rendra cette logique triviale à analyser. Pour la protéger, on va changer de paradigme : on va arrêter d'utiliser les instructions natives du processeur pour cette fonction.
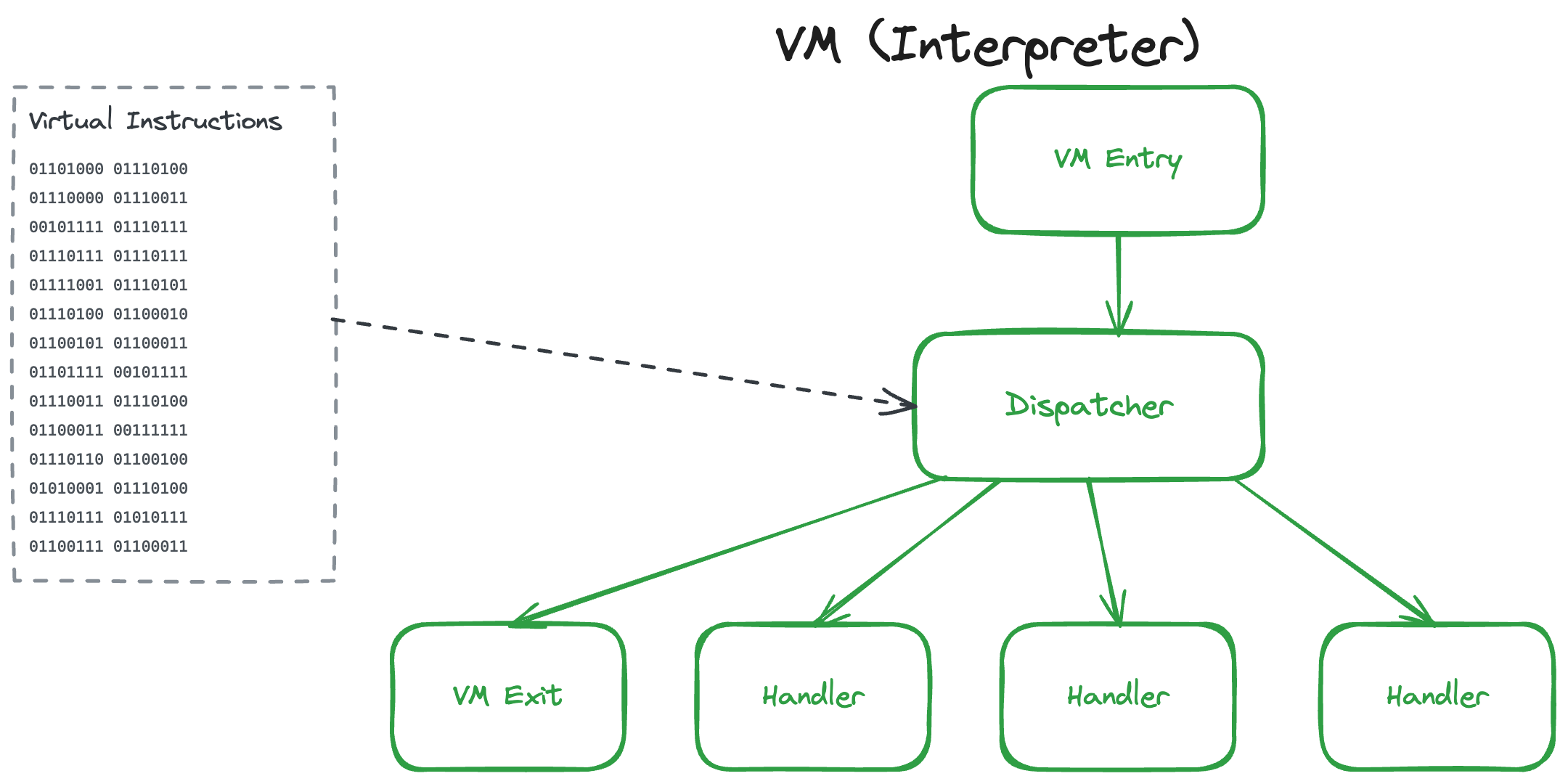
2. L'anatomie d'un virtualiseur
Pour transformer notre code, on a besoin de trois composants que j'ai implémentés dans mon outil.
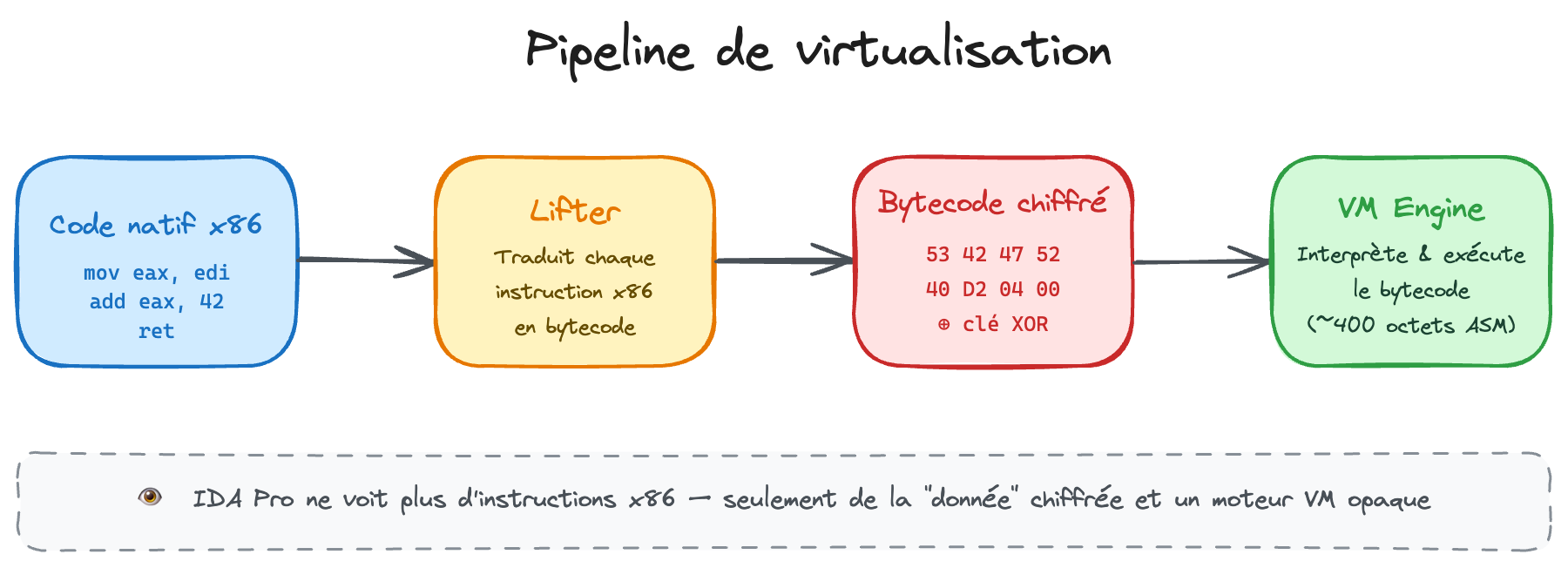
2.1. Le "Lifter" (Le traducteur)
Le Lifter est un script qui "lit" le binaire original. Il repère les instructions ADD, MOV, SUB et les traduit dans notre propre langage secret : le Bytecode.
Par exemple, notre ADD EAX, 42 devient une suite d'octets définie pour l'occasion : [0x10, 0x00, 0x2A, 0x00, 0x00, 0x00...]. Pour IDA, c'est juste de la donnée, pas du code.
2.2. Le "Bytecode" (Le langage secret)
Pour corser le truc, on ne stocke pas le bytecode en clair. Chaque octet est chiffré par XOR avec une clé dynamique. Si IDA regarde la section __bytecode, il verra ça :
53 42 47 52 40 D2 04 00 00 00 00 00 00 62 42 40
C'est du bruit. Sans la clé, impossible de deviner qu'il s'agit d'une addition.
Mieux encore, le jeu d'instructions (ISA) est généré aléatoirement à chaque compilation. Si l'instruction 0x01 signifie ADD dans la version 1.0, elle peut devenir XOR ou SUB dans la version 1.1. Cela rend l'automatisation du reverse engineering (via des scripts) quasiment impossible d'une version à l'autre.
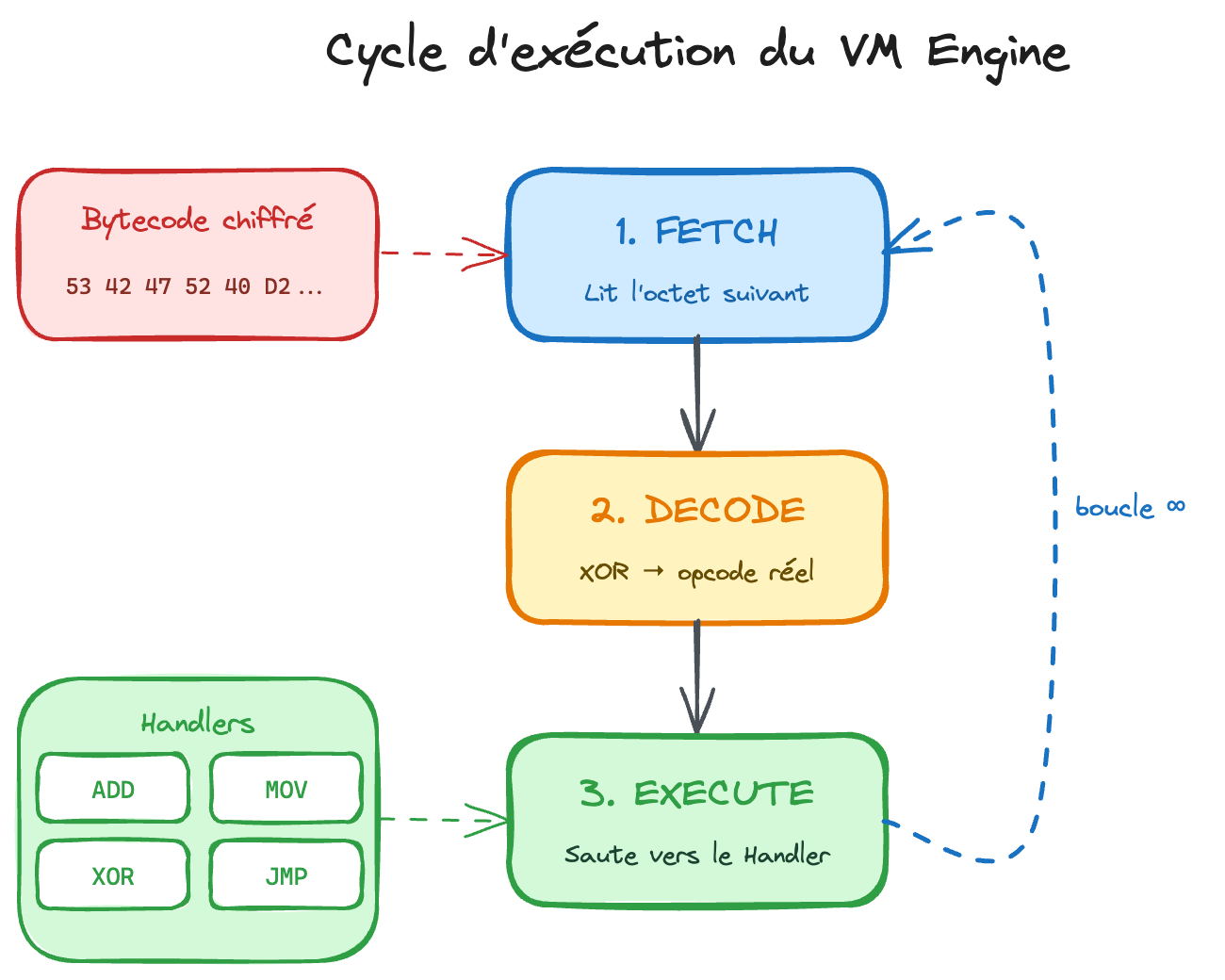
2.3. La "VM Engine" (L'interprète cursed)
C'est le cœur du système. C'est un morceau d'assembleur (environ 400 octets) injecté directement dans le binaire. Son rôle est de simuler un CPU. Elle possède ses propres registres virtuels.
Son cycle de vie est une boucle infinie :
- Fetch : Lit l'octet suivant du bytecode.
- Decode : Applique le XOR pour retrouver l'instruction réelle.
- Execute : Saute vers le "Handler" (le petit bout de code qui fait l'addition).
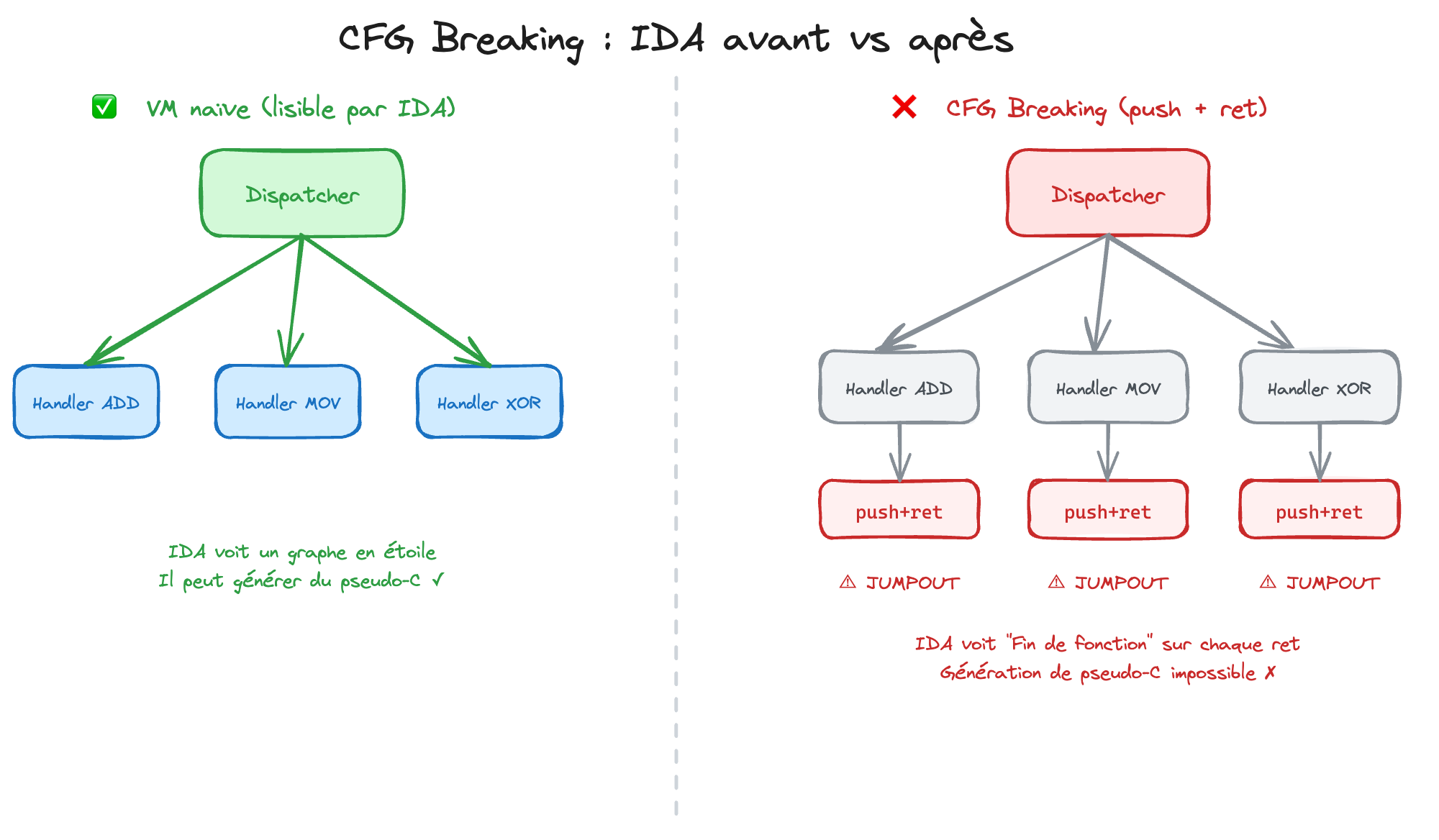
3. Comment rendre IDA Pro totalement aveugle ?
Si on se contente d'une boucle while classique, IDA va la décompiler proprement. On veut de la complexité. Pour ça, on utilise des techniques de "breaking".
3.1. Briser le Graphe de Flot (CFG Breaking)
Dans une VM normale, chaque instruction revient au dispatcher central. IDA voit une étoile avec un centre et des branches. C'est lisible.
Notre technique : Chaque handler finit par un push + ret.
- Le handler d'addition fait son calcul.
- Il calcule l'adresse du dispatcher.
- Il fait
push rax ; ret.
Pour IDA, un ret signifie "Fin de la fonction". Il s'arrête là. Résultat : IDA affiche un "Jumpout" et refuse de générer du code C. La fonction est brisée en mille morceaux déconnectés.
3.2. Le MBA (Mixed Boolean-Arithmetic)
Pour cacher une addition simple, on utilise des identités mathématiques booléennes complexes.
Au lieu de faire add rax, rbx, la VM fait ça :
# a + b => (a ^ b) + 2 * (a & b)
mov r8, rcx
xor r8, rdx ; r8 = a ^ b
and rcx, rdx ; rcx = a & b
shl rcx, 1 ; rcx = 2 * (a & b)
add r8, rcx ; r8 = result
Un analyste doit maintenant résoudre des équations logiques pour comprendre qu'on fait juste + 1234.
3.3. Le compromis : Performance vs Sécurité
On ne peut pas tout virtualiser. Le code exécuté par une VM est 10 à 100 fois plus lent que le code natif. Si on virtualisait le moteur de rendu d'un jeu, il tournerait à 1 FPS.
La stratégie consiste donc à cibler les "Hot Spots" : les fonctions de vérification de licence, les algorithmes de chiffrement ou la logique anti-triche. On sacrifie la vitesse sur 1% du code pour garantir l'intégrité des 99% restants.
4. Démonstration sur un Crackme
Prenons un programme qui demande un mot de passe numérique. La vérification est virtualisée.
Sans virtualisation, IDA affiche :
if ( input + 5575 == 15575 ) {
printf("OK");
}
Analyse et contournement immédiats.
Avec virtualisation, IDA affiche :
_check_logic:
lea r10, [rip + 0x1234] ; Charge le bytecode chiffré
jmp vm_engine ; Saute dans le moteur de virtualisation
retn ; <-- IDA s'arrête ici
Et si on regarde le moteur VM :
dispatcher:
...
retn ; <-- Jumpout !
Le décompilateur est incapable de sortir une seule ligne de C. La logique est noyée dans des centaines de sauts indirects et de calculs XOR.
5. La contre-attaque : L'Exécution Symbolique
La guerre ne s'arrête jamais. Les analystes les plus aguerris utilisent aujourd'hui des outils d'Exécution Symbolique comme Triton ou angr. Au lieu de lire le code, ces outils "résolvent" les équations mathématiques (comme les MBA vus plus haut) pour retrouver la logique originale.
C'est un jeu de chat et de souris permanent : plus les outils de dé-virtualisation progressent, plus les VM deviennent complexes.
Conclusion
La virtualisation déplace le combat : on ne protège plus son code, on protège l'architecture qui l'exécute.
- Le binaire est sain : Il tourne sans erreur.
- La logique est sauve : Elle n'existe plus sous forme d'instructions x86.
- L'analyste est fatigué : Il doit passer des heures à tracer la VM dans un debugger.
C'est une technique coûteuse en performance, mais c'est aujourd'hui le rempart le plus solide contre le reverse engineering.
Voilà, j'espère que ce tour d'horizon de l'obfuscation par virtualisation vous a plu ! Si vous voulez voir le code source de mon petit projet de virtualiseur en Rust, je l'open-sourcerai surement dans les prochaines semaines. En attendant, vous pouvez toujours vous amuser à créer votre propre VM pour protéger vos secrets les plus précieux. 😉